Design User System - Database & Memcache
用户系统
- 用户系统特点 读非常多,写非常少 一个读多写少的系统,一定要使用 Cache 进行优化
Scenario
DAU 1M
- 注册/登陆/信息修改
QPS = 1M * 0.1 / 86400 = 100 PEAK = 100 * 3 = 300 - 用户信息查询
QPS = 1M * 100 / 86400 = 100K PEAK = 100K * 3 = 300K
Service
Authentication Service

- Session Table 存在哪儿? 一般来说,都可以,即便存在 Cache 里,断电了相当于让所有用户都 logout 也没啥大不了 存在数据库里肯定更好 如果访问多的话,就用 Cache 做优化即可
FriendShip Service

FriendShip Service 如何选择数据库
- 数据库选择原则1 大部分的情况,用SQL也好,用NoSQL也好,都是可以的
- 数据库选择原则2 需要支持 Transaction 的话不能选 NoSQL
- 数据库选择原则3 你想不想偷懒很大程度决定了选什么数据库, SQL更成熟帮你做了很多事儿 NoSQL很多事儿都要亲力亲为(Serialization, Secondary Index)
- 数据库选择原则4 如果想省点服务器获得更高的性能,NoSQL就更好 硬盘型的NoSQL比SQL一般都要快10倍以上


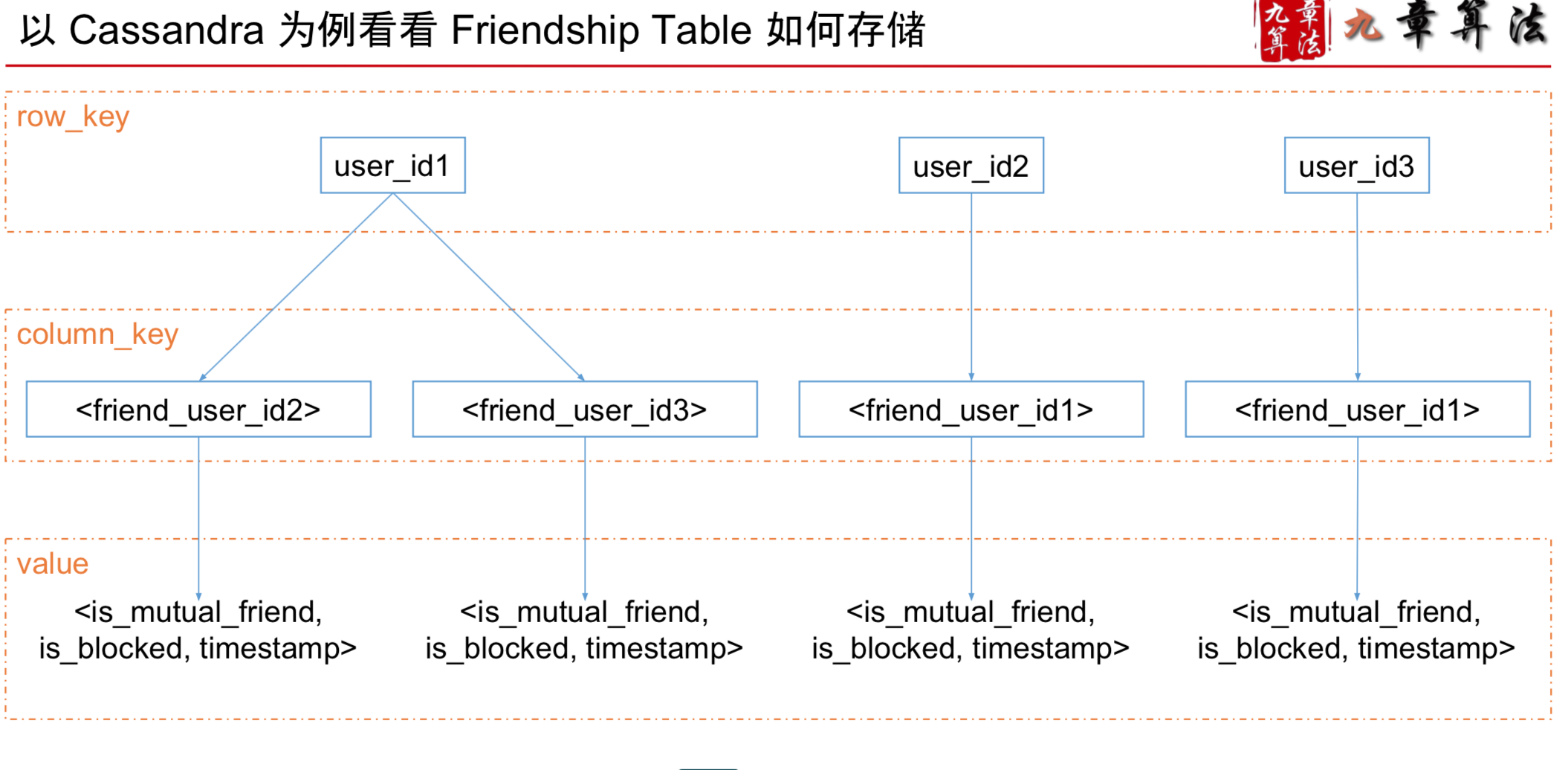
Storage
- Cache 只是个概念
Memcached 一款负责帮你Cache在内存里的“软件” 非常广泛使用的数据存储系统


对于 User System 而言, 写很少, 读很多
- 写操作很少,意味着
- 从QPS的角度来说,一台 MySQL 就可以搞定了 • 读操作很多,意味着
- 可以使用 Memcached 进行读操作优化
- 进一步的问题,如果读写操作都很多,怎么办?
- 方法一:使用更多的数据库服务器分摊流量
- 方法二:使用像 Redis 这样的读写操作都很快的 Cache-through 型 Database
- Memcached 是一个 Cache-aside 型的 Database,Client 需要自己负责管理 Cache-miss 时数据的 loading
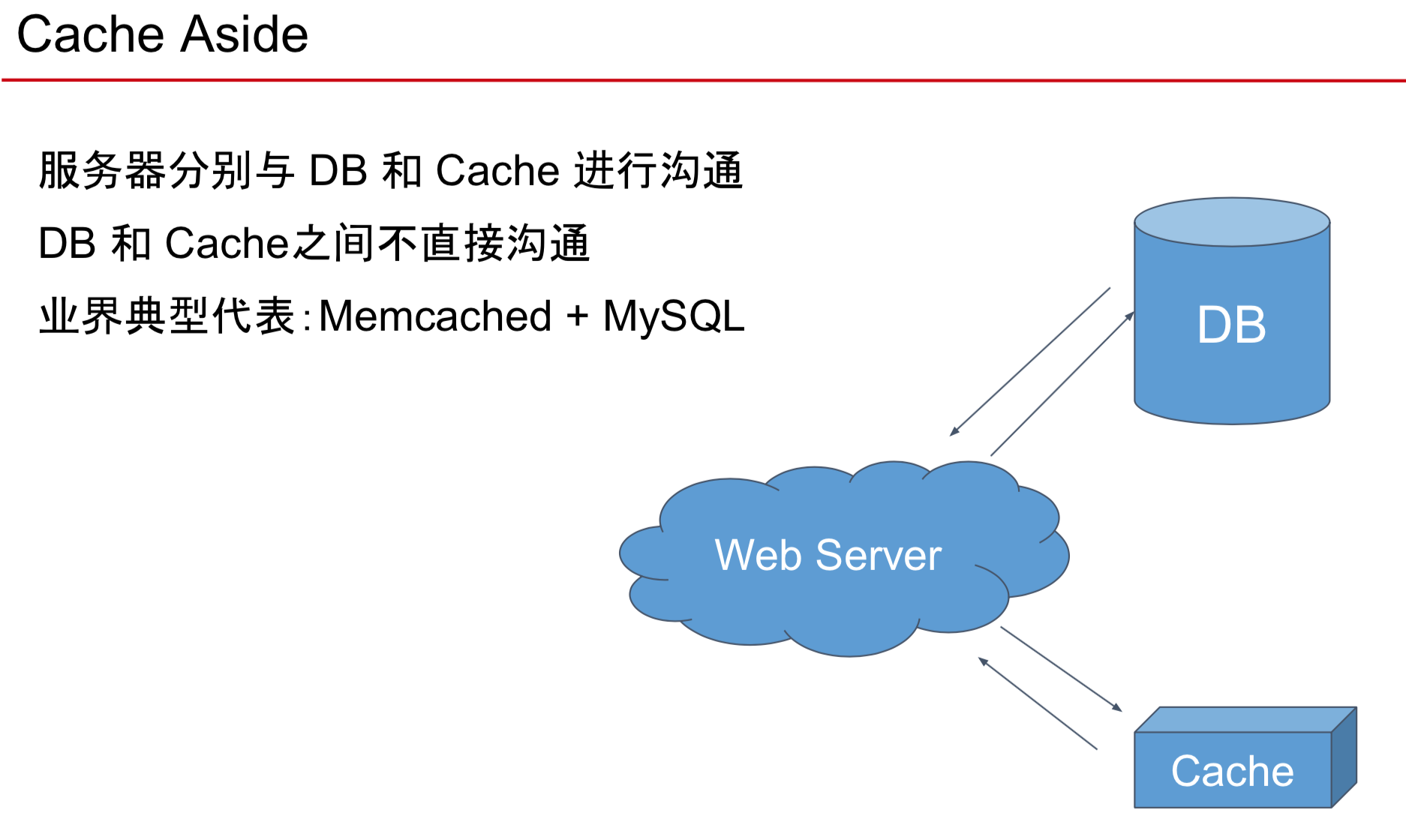
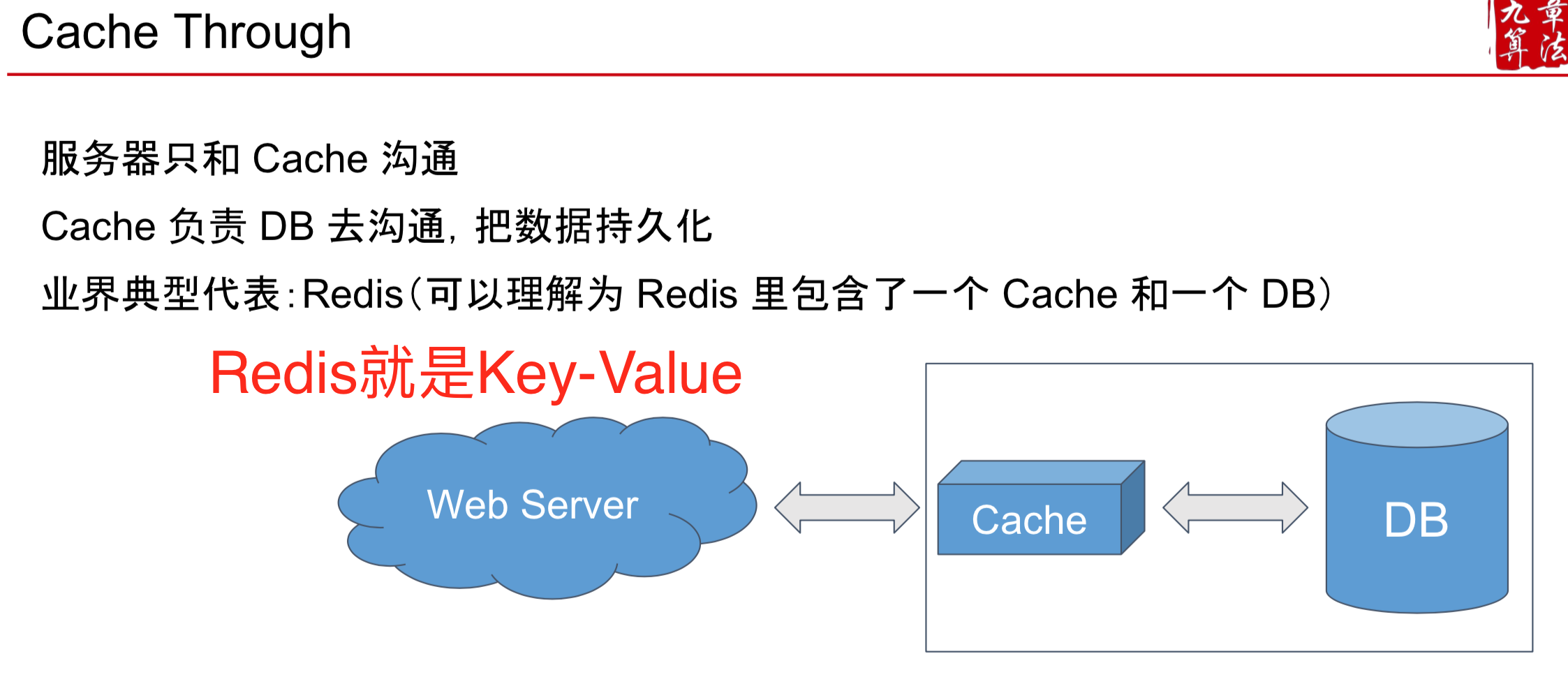
Scale
- 100M 的用户存在一台 MySQL 数据库里也存得下,Storage没问题,通过 Cache 优化读操作后,只有 300QPS 的写,QPS也没问题 还有什么问题?
- Single Point Failure 万一这一台数据库挂了 短暂的挂:网站就不可用了 彻底的挂:数据就全丢了
接下来两件事情
- 数据拆分 Sharding
- 按照一定的规则,将数据拆分成不同的部分,保存在不同的机器上 • 这样就算挂也不会导致网站 100% 不可用
- 数据备份 Replica
- 通常的做法是一式三份(重要的事情“写”三遍) • Replica 同时还能分摊读请求
Sharding 数据的分发规则
- SQL自身不带 Sharding 功能,需要码农亲自上手 Cassandra为例的NoSQL大多数都自带 Sharding
两种Sharding 方式
Vertial Sharding
- User table一台机器, Friendship 一台机器, Message Table一套机器
- 问题就是是按表去拆分的,而不是按访问量均摊,比如Message Table可能比Friendship访问量大5倍
- 这样就导致了分工不均
稍微复杂一点的Vertical Sharding
还是这个User table 我们知道 email / username / password 不会经常变动
• 而 status_text, avatar 相对来说变动频率更高
• 可以把他们拆分为两个表 User Table 和 User Profile Table • 然后再分别放在两台机器上
• 把UserProfile 跟friendship放在一起
• 这样如果 UserProfile Table 挂了,就不影响 User 正常的登陆
Horizontal Sharding
- 把每个表都分开,通过key去找到是哪个机器上
Horizontal Sharding 的问题1
假如我们来拆分 Friendship Table
我们有10台数据库的机器 于是想到按照 from_user_id % 10 进行拆分 这样做的问题是啥?
我现在新买了1台机器
原来的%10,就变成了%11 几乎所有的数据都要进行位置大迁移
过多的数据迁移会成的问题 1. 慢,牵一发动全身
2. 迁移期间,服务器压力增大,容易挂 3. 容易成数据的不一致性
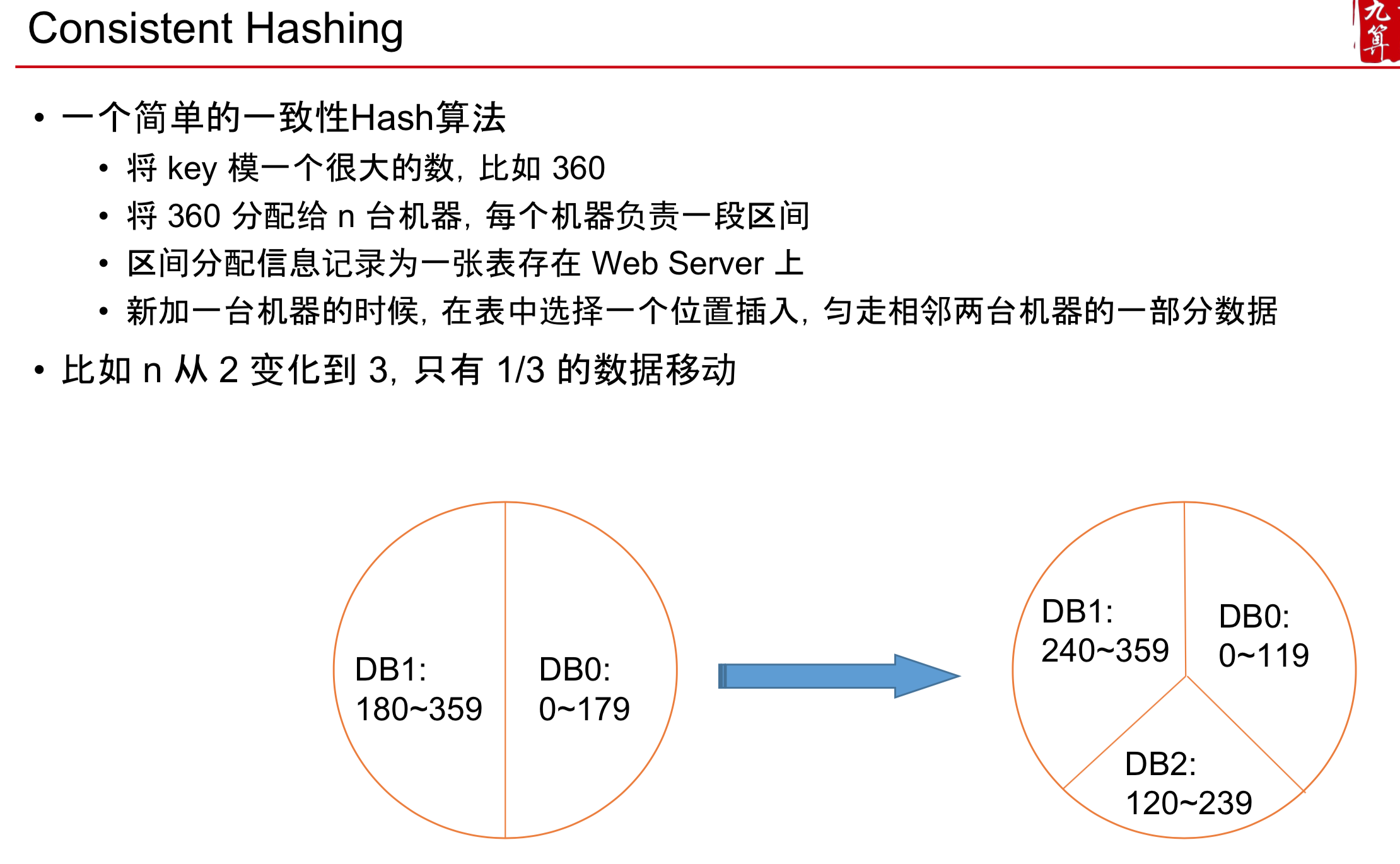
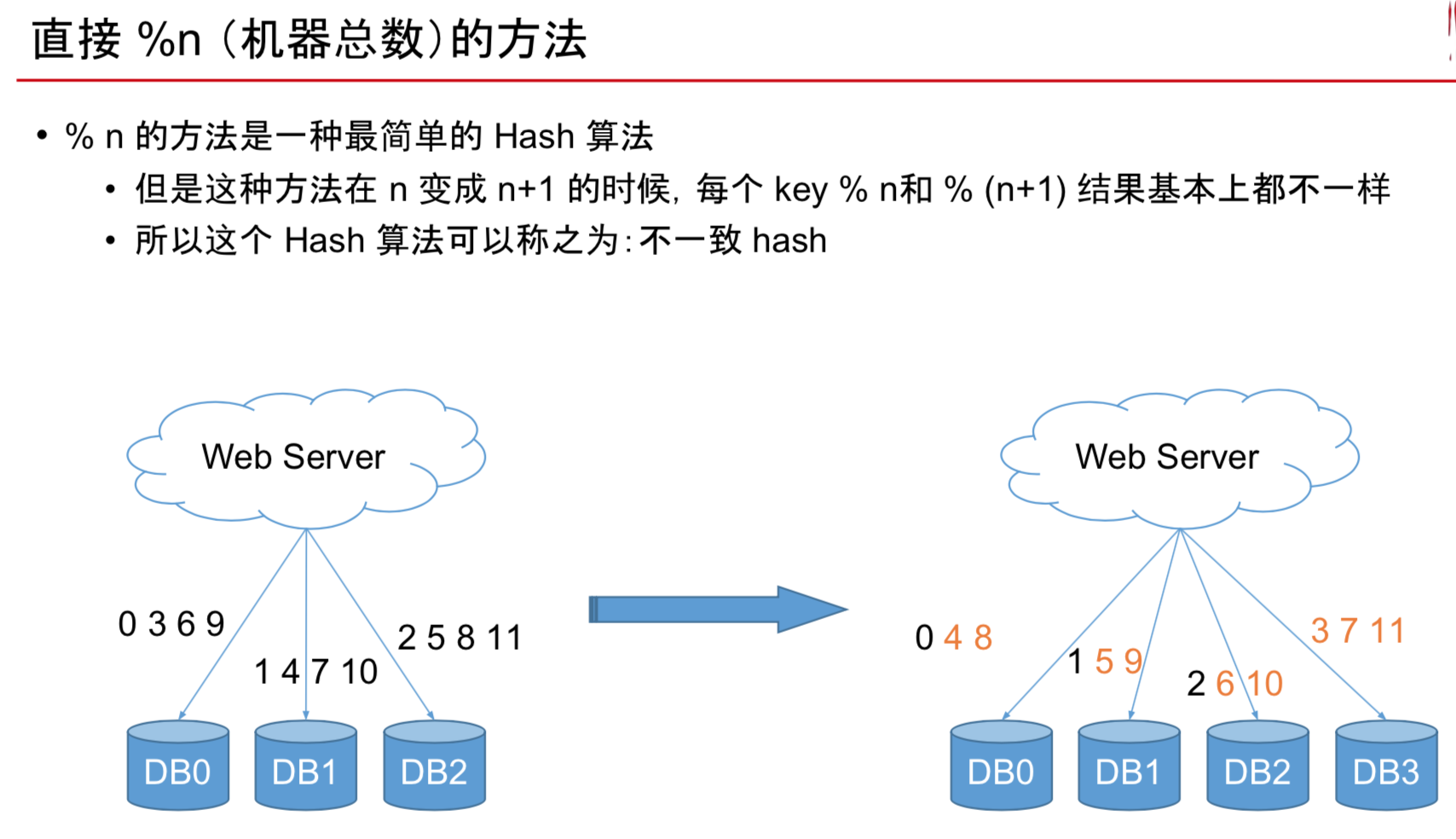 如上图,这样就导致了75%的数据迁移
如上图,这样就导致了75%的数据迁移
- 解决办法: 一致性 Hash 算法 Consistent Hashing
Horizontal Sharding 的问题2
User Table 如果被按照 user_id 进行 sharding 了之后,如何支持按照 email 查询某个用户的信息?
- 再建一个表,按照email进行sharding
- 只需要存email -> userID, 然后再回user table找
- 不能存email -> 所有data, 这样极大增大 数据不一致 的危险
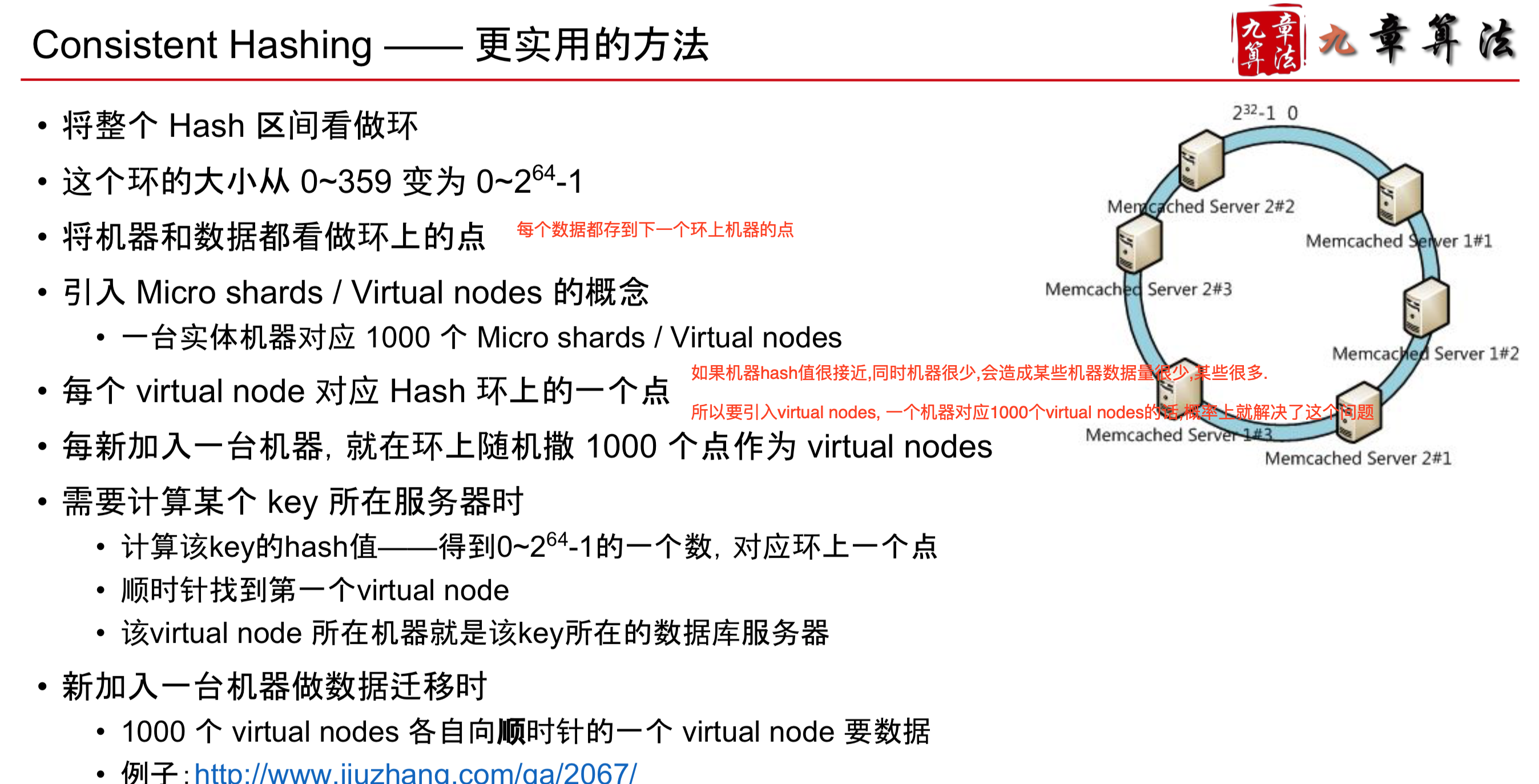
Consistent Hashing
- 无论是 SQL 还是 NoSQL 都可以用这个方法进行 Sharding. 区别只是 NoSQL 帮你实现了,SQL 你自己动手写
- 这样Consistent Hashing存在一点问题,需要优化
缺陷1 数据分布不均匀 因为算法是“将数据最多的相邻两台机器均匀分为三台”
比如,3台机器变4台机器时,无法做到4台机器均匀分布
缺陷2 迁移压力大 新机器的数据只从两台老机器上获取
导致这两台老机器负载过大
- 用一个数组来保存环上的所有的hashing的机器点,唯一不好是在添加机器后,需要重新排序生成数组
- 这样就可以二分法去检索
- 也可以treeset或者treemap去检索
Replica
- SQL
MySQL Replica 以MySQL为代表SQL型数据库,通常“自带” Master Slave 的
Replica 方法
Master 负责写,Slave 负责读 Slave 从 Master 中同步数据

Write Ahead Log 常用语Transaction, 所以失败的时候可以从这里恢复
- NonSQL
NoSQL Replica
以 Cassandra 为代表的 NoSQL 数据库
通常将数据“顺时针”存储在 Consistent hashing 环上的三个 virtual nodes 中
SQL
“自带” 的 Replica 方式是 Master Slave
“手动” 的 Replica 方式也可以在 Consistent Hashing 环上顺时针存三份
NoSQL
“自带” 的 Replica 方式就是 Consistent Hashing 环上顺时针存三份
“手动” 的 Replica 方式:就不需要手动了,NoSQL就是在 Sharding 和 Replica 上帮你偷懒用的!
BackUp
Backup
• 一般是周期性的,比如每天晚上进行一次备份
• 当数据丢失的时候,通常只能恢复到之前的某个时间点
• Backup 不用作在线的数据服务,不分摊读
Replica
• 是实时的, 在数据写入的时候,就会以复制品的形式存为多份
• 当数据丢失的时候,可以马上通过其他的复制品恢复
• Replica 用作在线的数据服务,分摊读
既然 Replica 更牛,那么还需要 Backup么?
- Replica 成本比较高
- Replica 是保存最新的数据,但是backup可以放去之前的数据,可以起记录的作用
- backup的效率会高很多