Location Based Service
一些各家的技术介绍

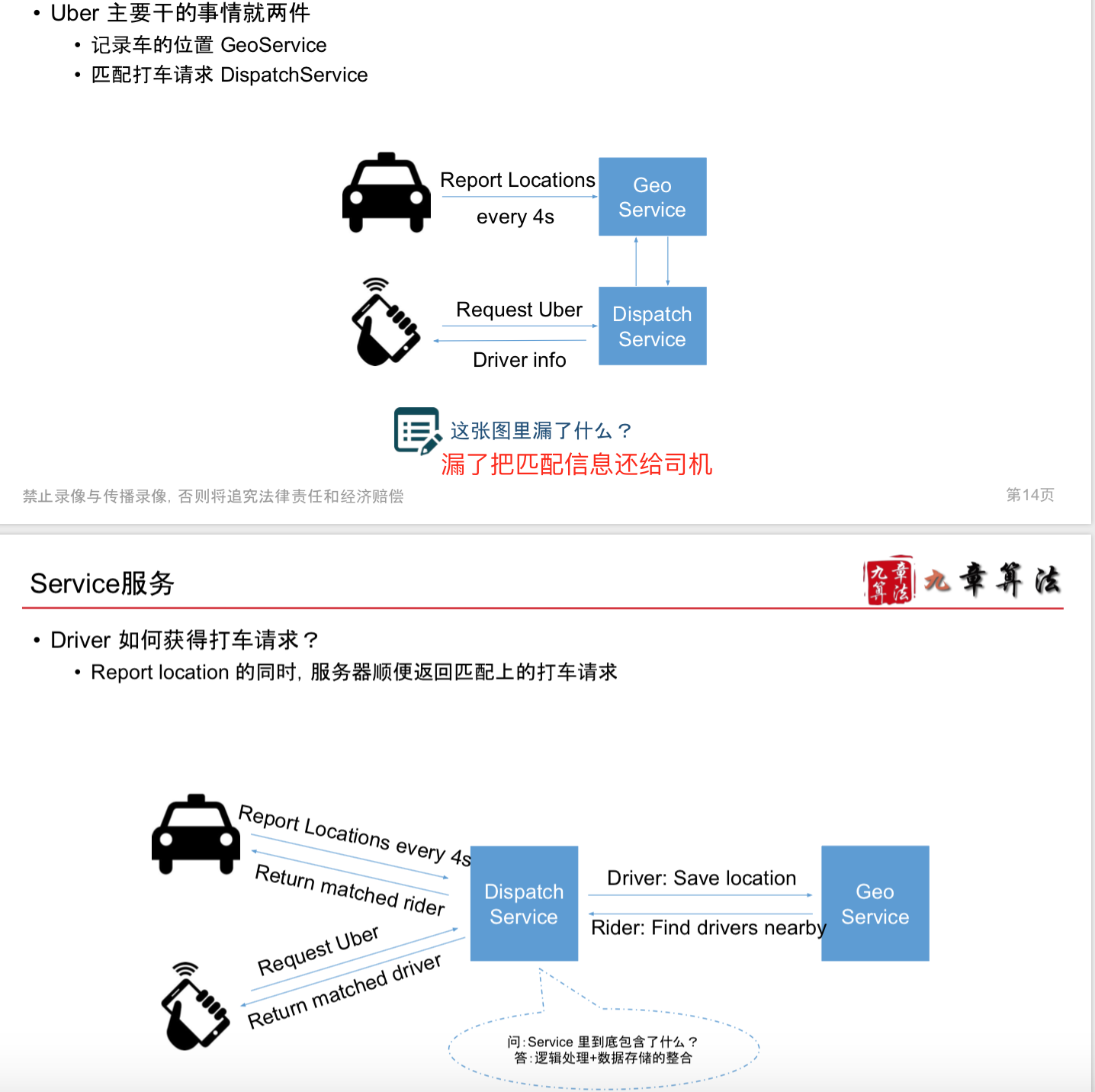
Scenario

Service
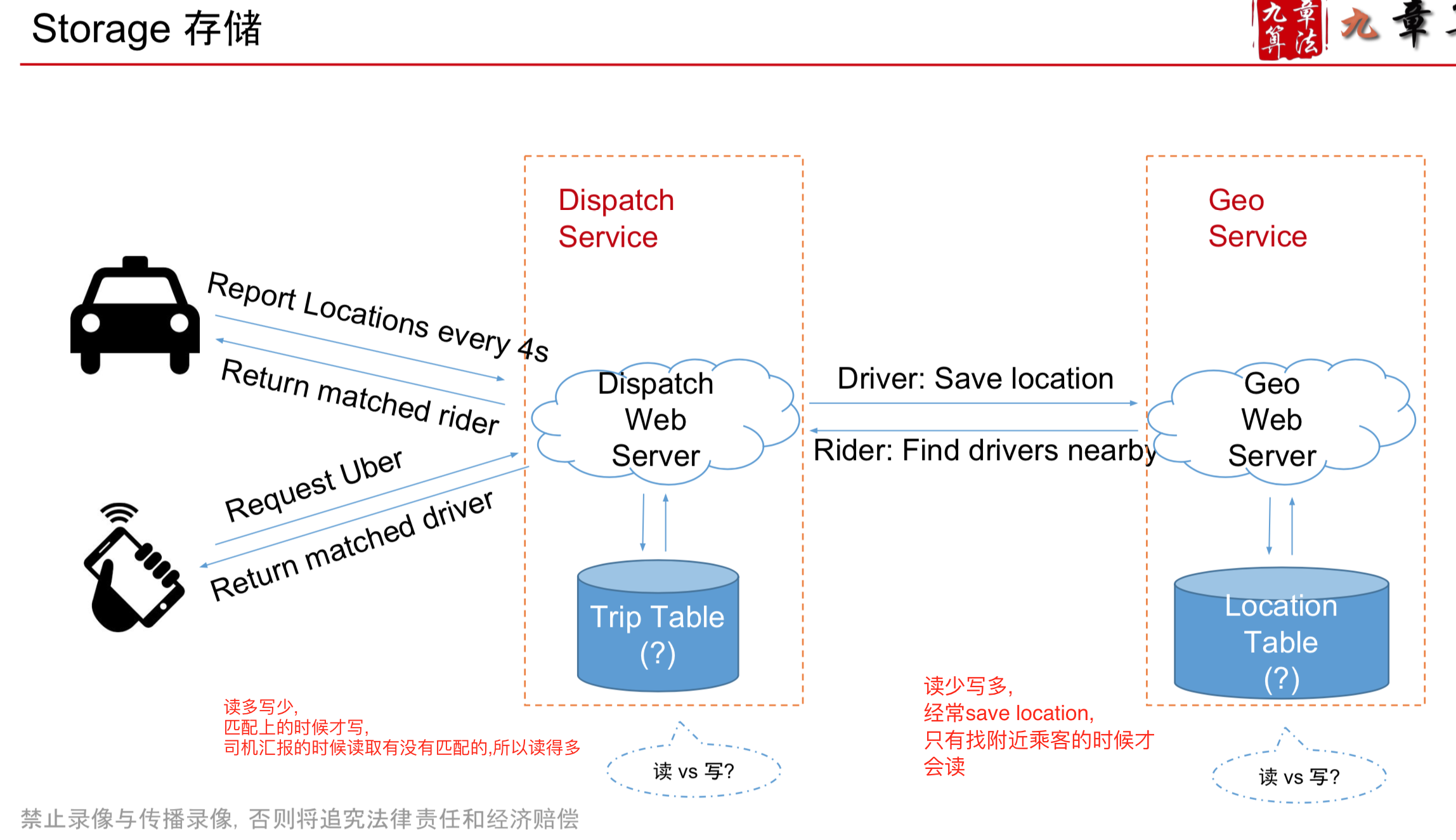
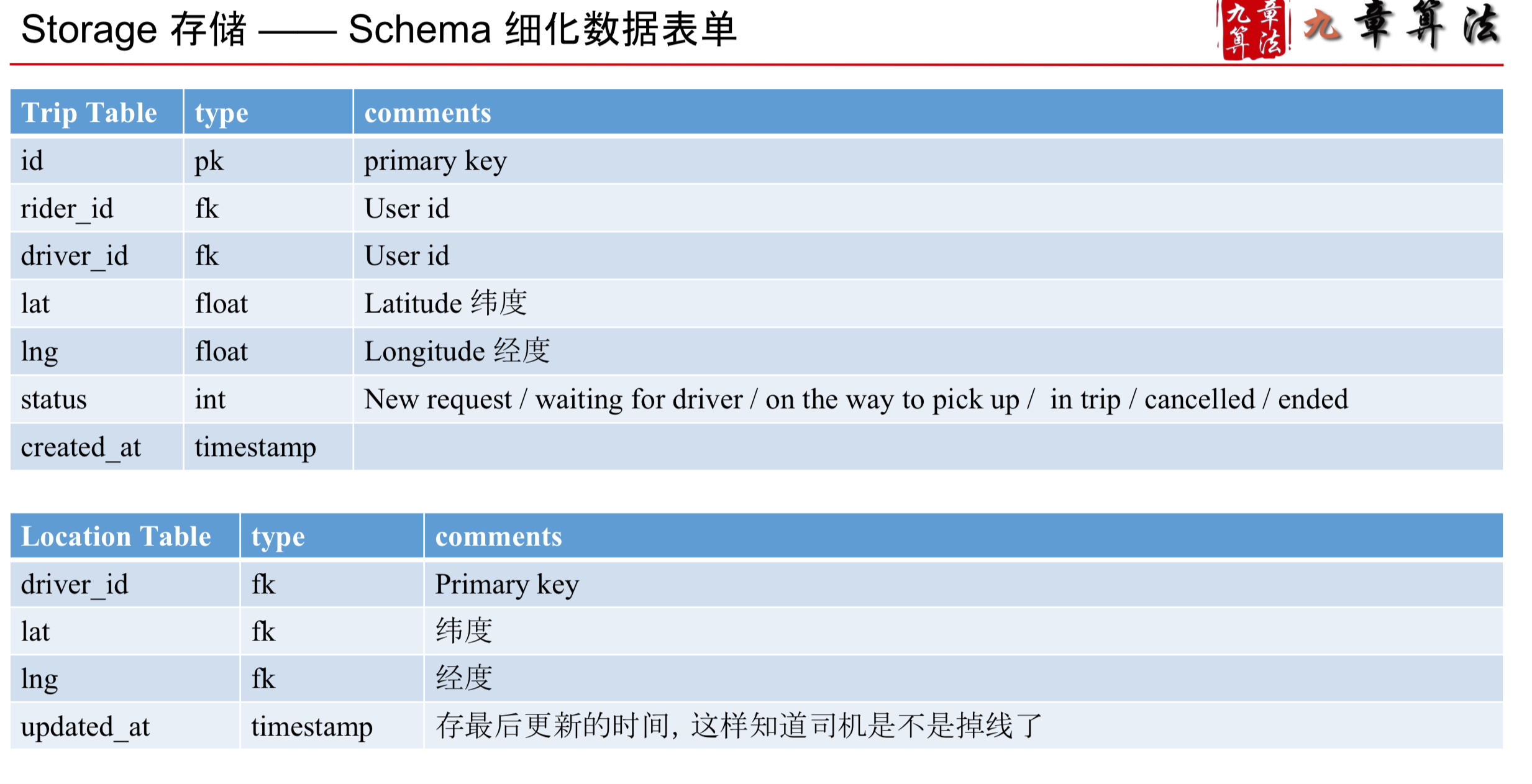
Storage
算法
最笨的办法
SELECT * FROM Location
WHERE lat < myLat + delta
AND lat > myLat - delta
AND lng < myLng + delta
AND lng > myLng - delta;
——这个基本等同于扫描了一遍所有的数据,数据量太庞大了
也不可能先把位置进行了排序,排序的时间太久了
而且使用了两个column 的 range query
Google S2
• Read more • Hilbert Curve • 将地址空间映射到2^64的整数 • 特性:如果空间上比较接近的两个点,对应的整数也比较接近 • Example: (-30.043800, -51.140220) → 10743750136202470315 • 更精准,库函数API丰富
Geohash
• Read more • Peano Curve • Base32:0-9, a-z 去掉 (a,i,l,o) • 为什么用 base32 ? 因为刚好 25 可以用 5 位二进制表示 • 核心思路二分法 • 特性:公共前缀越长,两个点越接近 • Example: (-30.043800, -51.140220) → 6feth68y4tb0 • 比较简单,准确度差一些
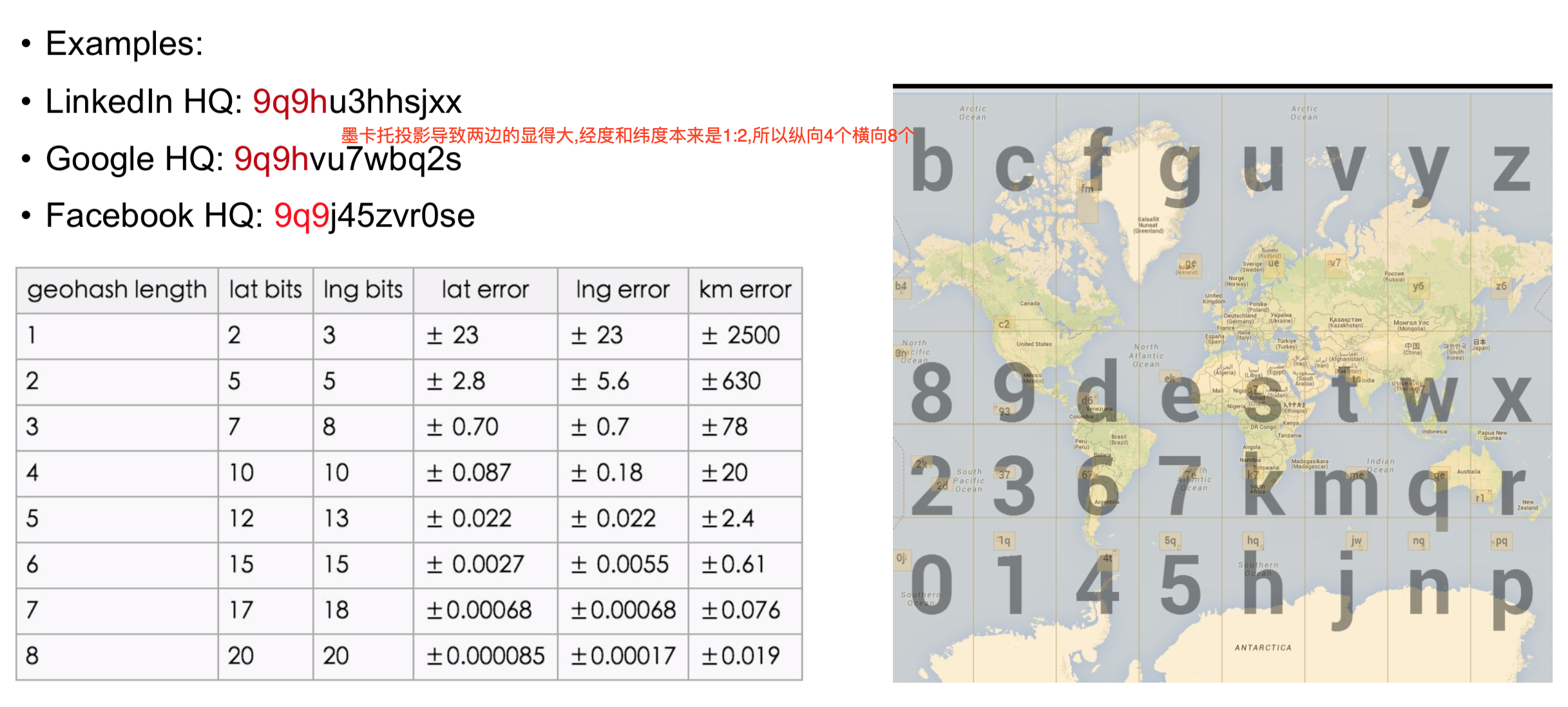

查询Google半径2公里内的车辆
- 找到精度误差 > 2公里的最长长度
- Google HQ: 9q9hvu7wbq2s
- 找到位置以9q9hv以开头的所有车辆
Storage
SQL 数据库
- 首先需要对 geohash 建索引
- CREATE INDEX on geohash;
- 使用 Like Query
- SELECT * FROM location WHERE geohash LIKE
9q9hv%;
NoSQL - Cassandra
- 将 geohash 设为 column key
- 使用 range query (9q9hv0, 9q9hvz)
NoSQL - Redis / Memcached
- Driver 的位置分级存储
- 如Driver的位置如果是9q9hvt,则存储在9q9hvt,9q9hv,9q9h这3个key中 • 6位geohash的精度已经在一公里以内,对于Uber这类应用足够了
- 4位geohash的精度在20公里以上了,再大就没意义了,你不会打20公里以外的车
- key = 9q9hvt, value = set of drivers in this location
- 为什么用set而不用list? 因为经常会有车出去,车进来,所以要支持很快的add和remove
Storage比较
SQL 可以,但相对较慢
- 原因1:Like query 很慢,应该尽量避免 • 即便有index,也很慢
- 原因2:Uber 的应用中,Driver 需要实时 Update 自己的地理位置 • 被index的column并不适合经常被修改
- B+树不停变动,效率低
NoSQL – Cassandra 可以,但相对较慢
- 原因: Driver 的地理位置信息更新频次很高
- Column Key 是有 index 的,被 index 的 column 不适合经常被“修改”
NoSQL – Memcached 并不合适
- 原因1:Memcached 没有持久化存储,一旦挂了,数据就丢失 • 原因2:Memcached 并不原生支持 set 结构
- 需要读出整个set,添加一个新元素,然后再把整个set赋回去
NoSQL - Redis
- 数据可持久化 原生支持list,set等结构
- 写速度接近内存访问速度 >100k QPS
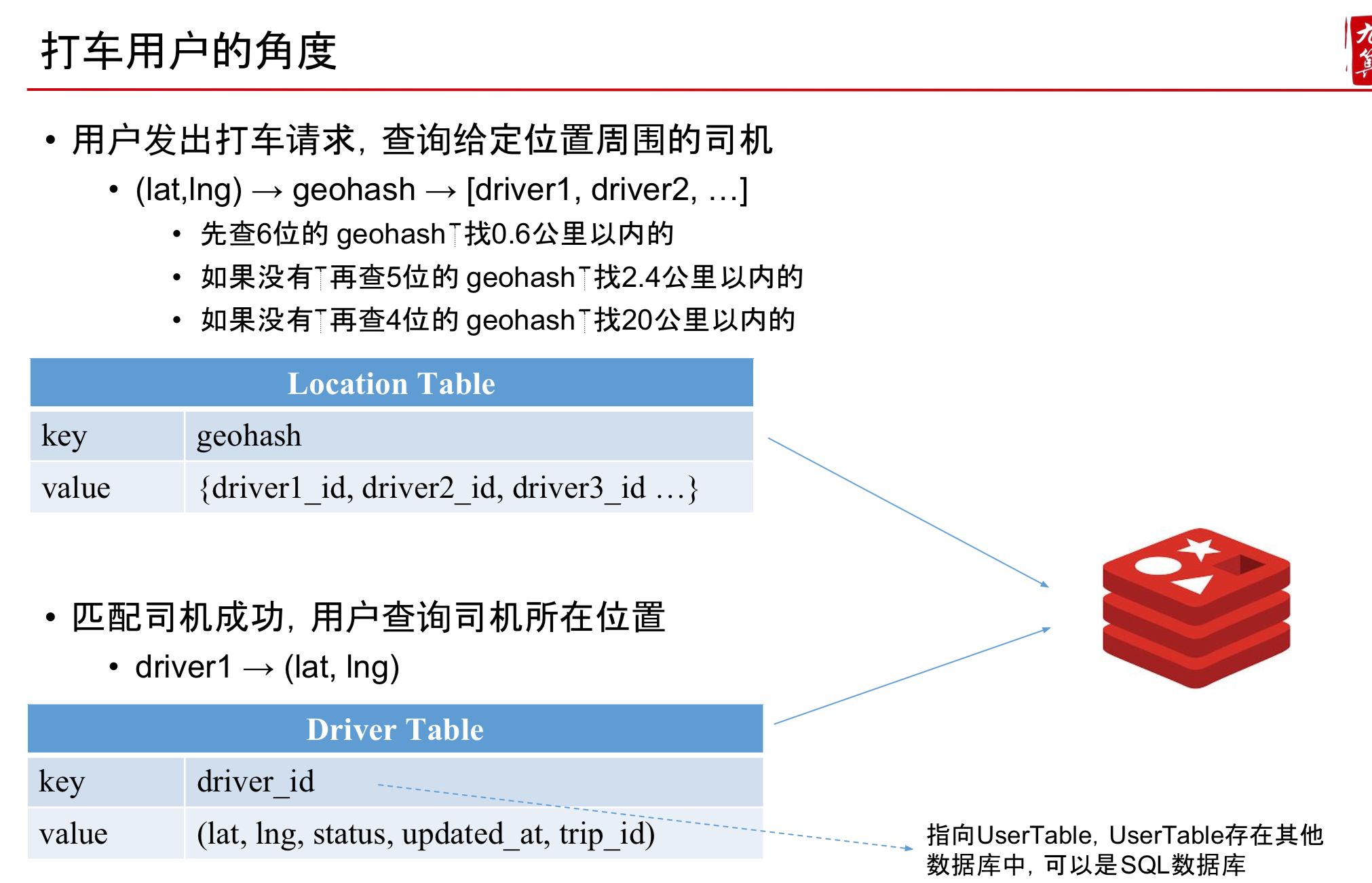
Work Soluction
- 乘客发出打车请求,服务器创建一次Trip
- 将 trip_id 返回给用户
乘客每隔几秒询问一次服务器是否匹配成功
服务器找到匹配的司机,写入Trip,状态为等待司机回应
同时修改 Driver Table 中的司机状态为不可用,并存入对应的 trip_id
司机汇报自己的位置
顺便在 Driver Table 中发现有分配给自己的 trip_id • 去 Trip Table 查询对应的 Trip,返回给司机
司机接受打车请求
修改 Driver Table, Trip 中的状态信息 • 乘客发现自己匹配成功,获得司机信息
司机拒绝打车请求
- 修改 Driver Table,Trip 中的状态信息,标记该司机已经拒绝了该trip • 重新匹配一个司机,重复第2步
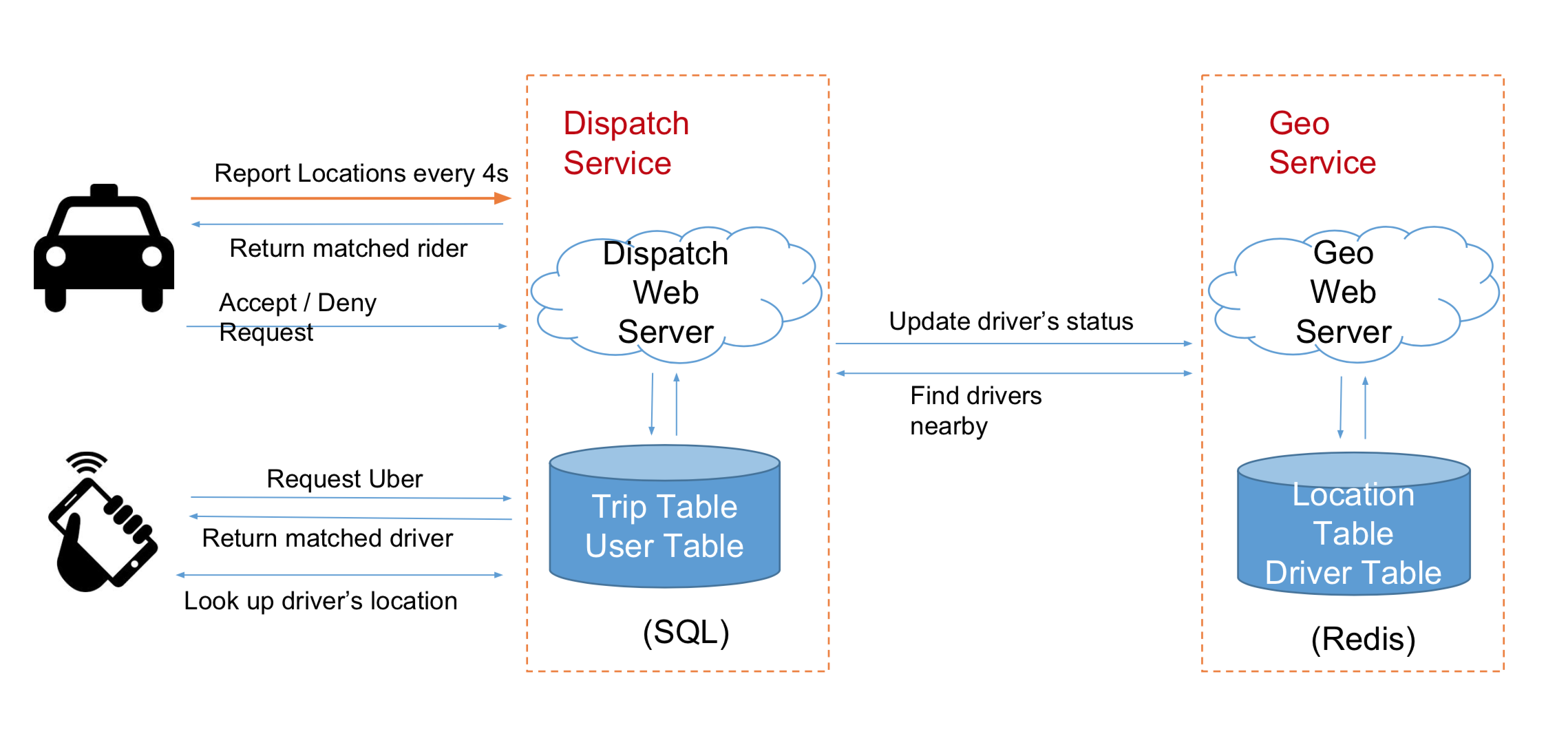
Scale
- 需求是150k QPS
- Redis 的读写效率 > 100 QPS 是不是1-2台就可以了?
Soluction: DB Sharding
- 目的1:分摊流量
- 目的2:Avoid Single Point Failure
按照什么来Sharding? 按照城市Sharding
- shading的目的:因为用户请求时基于位置的
- 难点1:如何定义城市?
- 难点2:如何根据位置信息知道用户在哪个城市?
如何判定城市
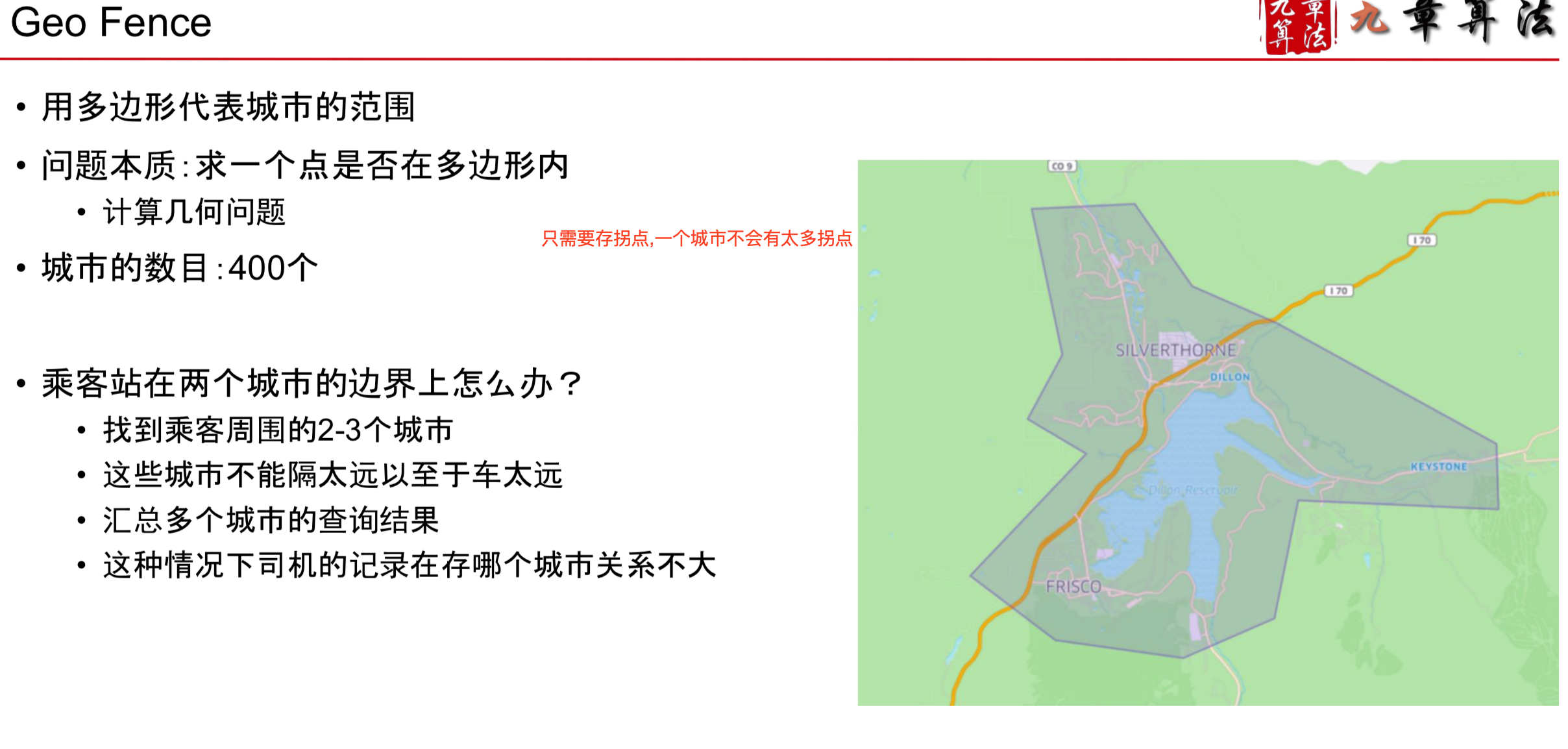
- 或者有的也可以根据行政区域来划分城市,因为可能政策不一样
How to check rider is in Airport? 同样可以用Geo Fence
类似机场这样的区域有上万个,直接O(N)查询太慢 分为两级Fence查询,先找到城市,再在城市中查询Airport Fence
How to reduce impact on db crash?
- 多台 Redis 虽然能减少损失 但是再小的机器挂了,都还是会影响
