Crawler
- For collectiing data/information from the web
- 爬的时候,就是一个有向图, url1 -> url2 -> url3/url4
- 从种子店触发,找到联通的点,BFS
- 可能碰到环形到重复的节点
- 量太大, 很有可能爆内存
- 所以既要考虑QPS,还要考虑到内存,disk
Field related to Crawler
- multi-threading
- system design
爬虫
- a simplistic news crawlerService
- a simplistic web crawlerService
- a single-threaded web crawler
- a multi-threaed web crawler
simplistic news crawlerService
- given the URL of news list pages
- send HTTP request and grab content
- extract news title from news list page, 使用regular expressions
Python 比如 import urllib2
request = urllib2.Request(url)
response = urllib2.urlopen(request)
page = response.read()
single threaded web crawlerService
- 单线程Crawler, 用MQ, 比如Kafka, Rabit等
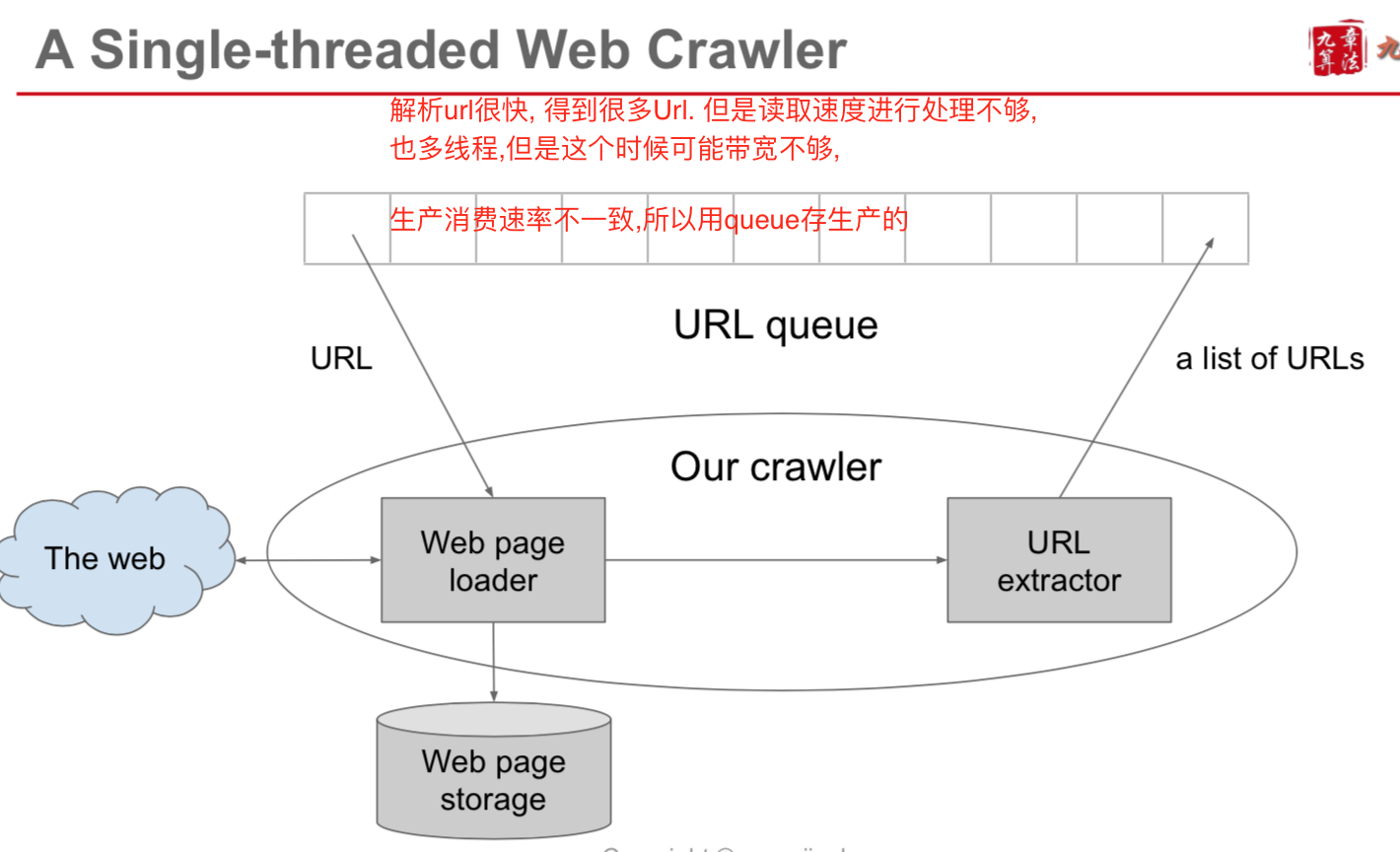

multi threaded web crawlerService
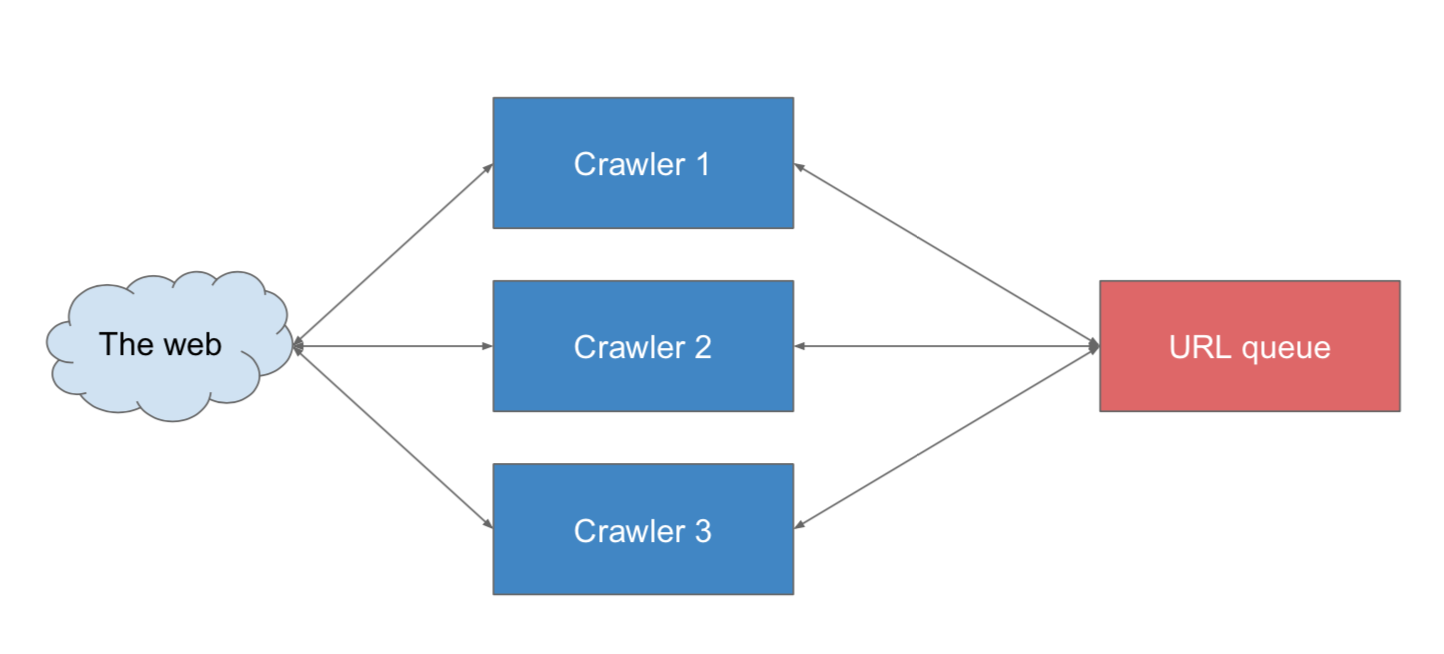
- 在 1 trillion级别的数据量下, 在内存中queue也是不够的,我们要利用db
- 针对每个网页,抓取的重要性频率也是不一样的,
- 而且queue可能会经常重复抓取 (比如thread1 在爬 web1, thread2也可能在爬)
- 用一个task table记录state和priority会更好
- 在task table里边,把大网站拆分开来,见图,把sina拆成好多个,不然一个thread承受不住
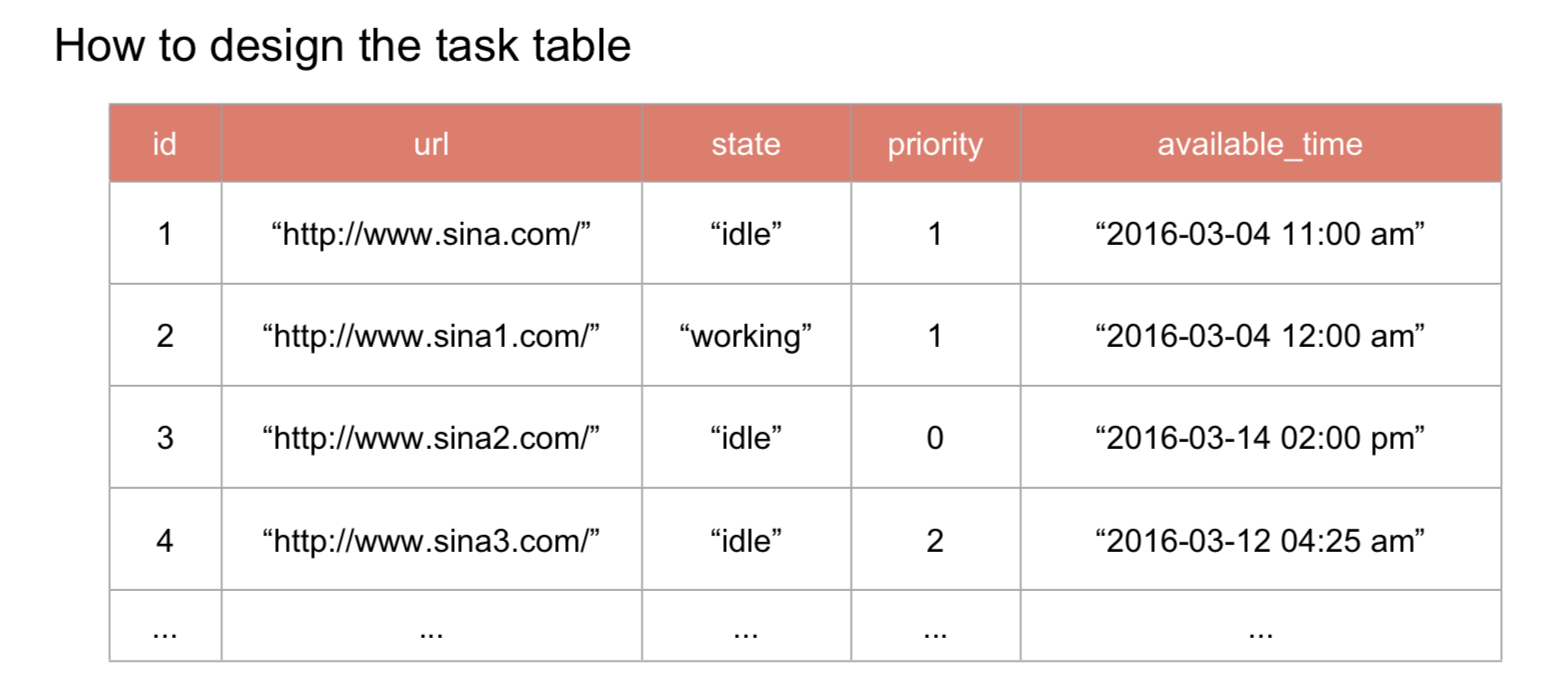
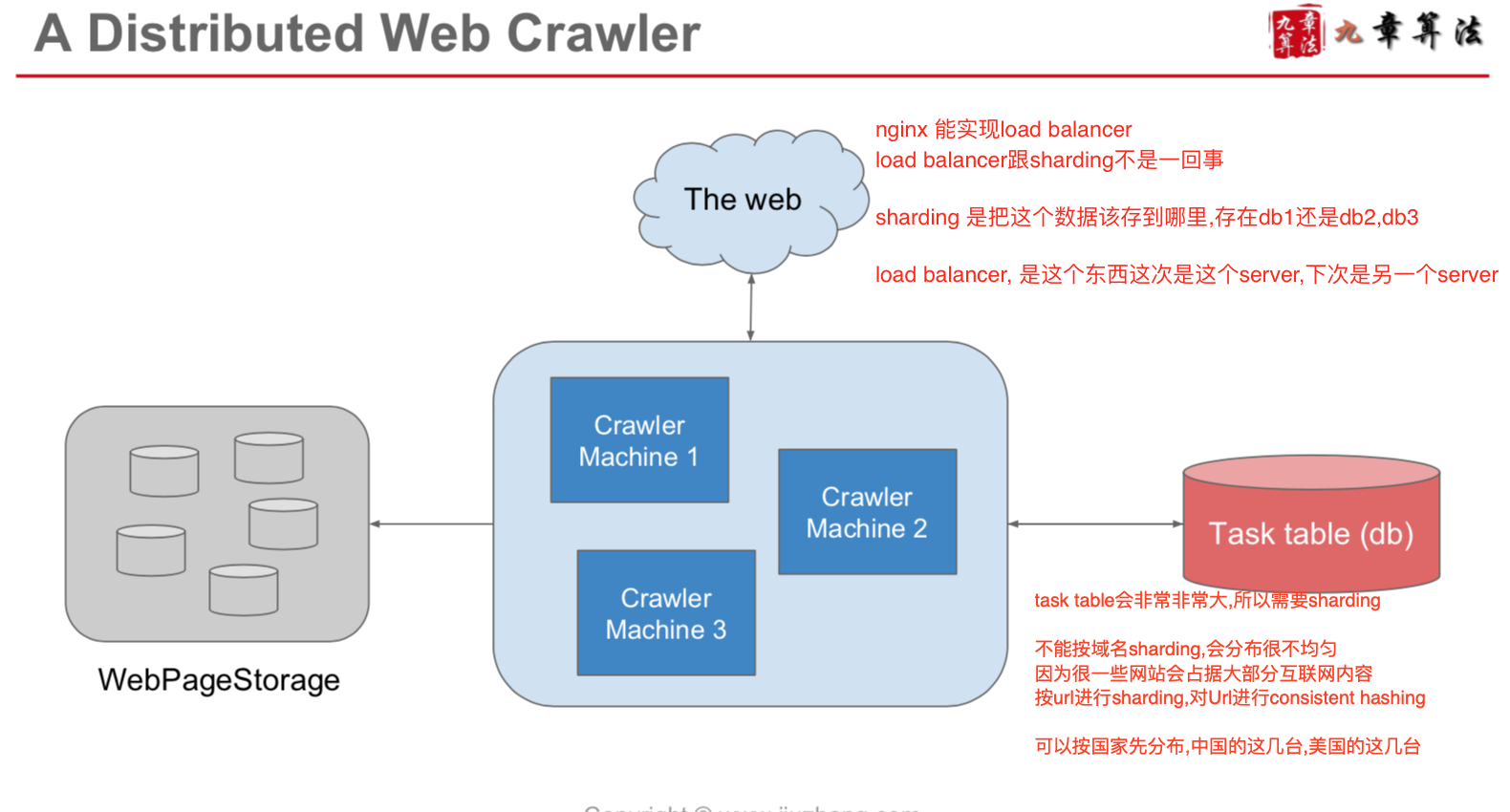
- 用sharding,去防止slow select
线程不是越多越好,多了也会出现很多问题
- context switch cost(CPU number limitation), 线程切换的成本
- thread port number limitation, 端口有限
- 带宽也是有限的,最好读网页和解析达到一个平衡,所以开始考虑多机多线程而不是单机多线程
多线程怎么合作的?
- sleep
- condition variable
- semaphore
How Google search engine use crawler
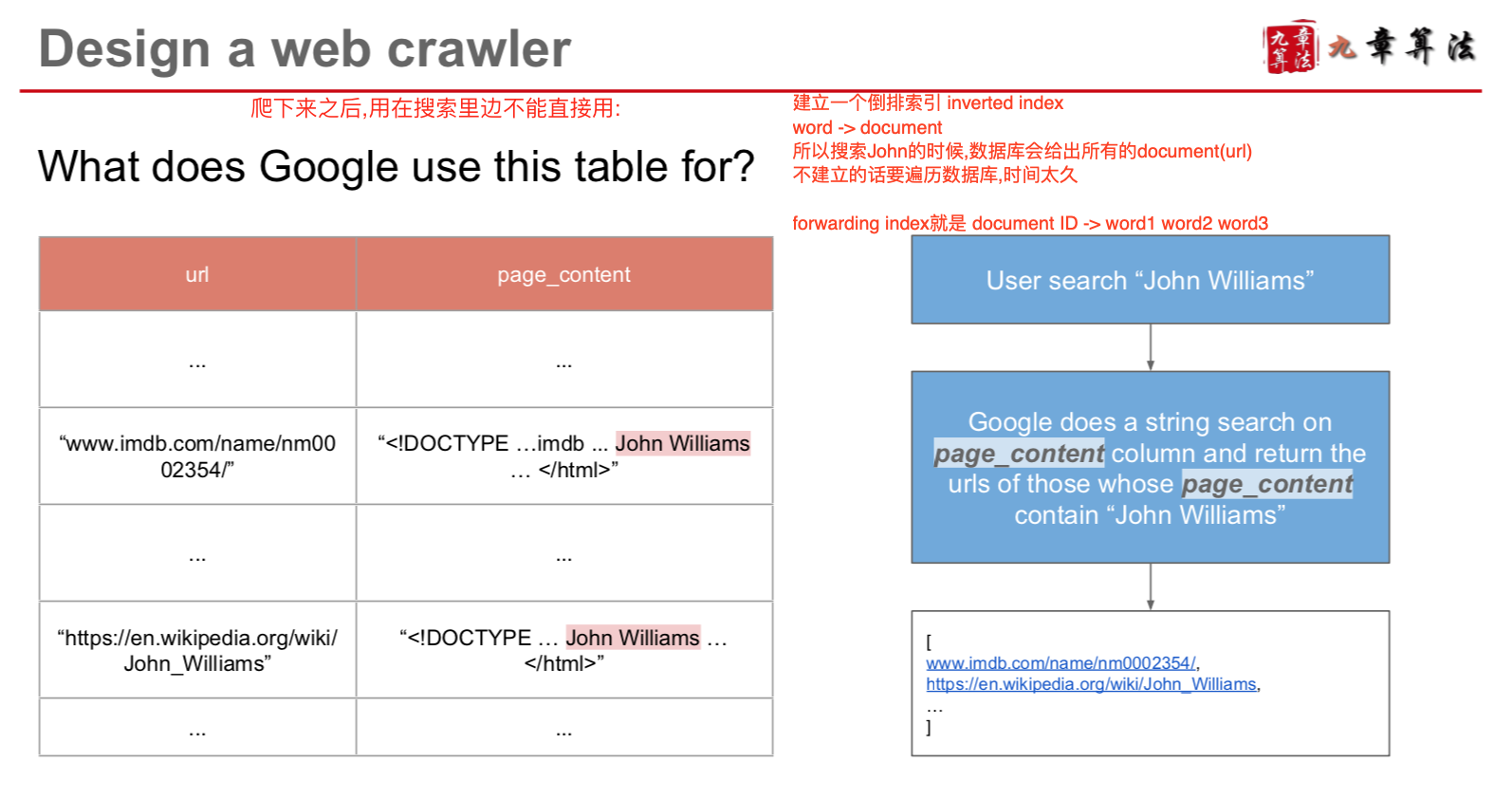
Scenario
- 1 trillion web pages, one week
- => 1.6m web pages per second
- 网页平均大小 1KB
- 那么需要10PB
- 不可能放到内存里边去做,只能放到磁盘里边
- 还有个问题,同一个网页,一个更新频繁的网站可能需要经常爬去,有的小网站需要过很多爬一次 , 这样既就需要动态实时的爬去
Service
- Crwaler, TaskService(需要一个producer-consumer模型), StorageService
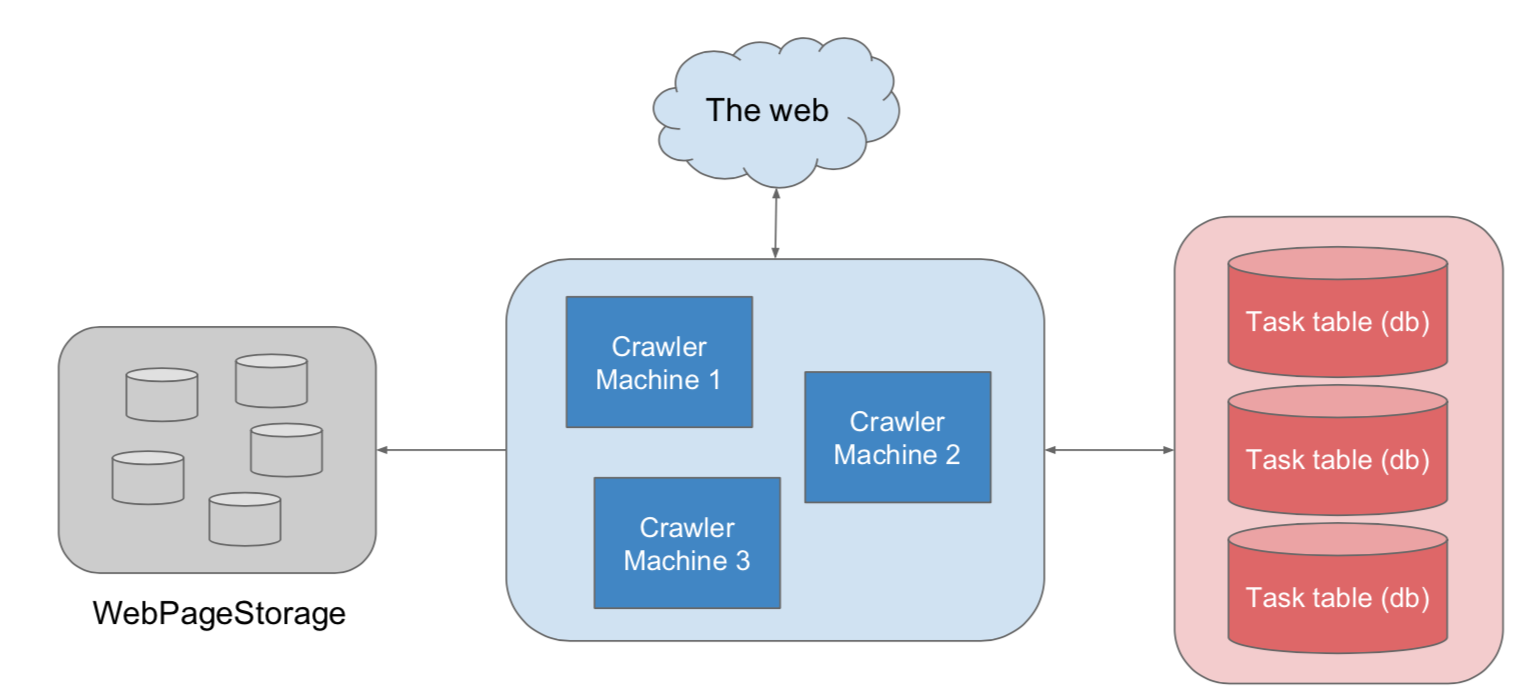
Storage
- db to store tasks, bigtable to store web pages
Scale
How to handle update for failure?
- 爬虫经常容易失败,各种各样的原因
- 这个时候可以使用 Exponential back-off
- 否则一直失败的话,一直去爬它,就会浪费很多资源
- 如果成功,下次一周之后再爬
- 如果第一次失败,两周之后再爬
- 如果第二次失败,四周之后再爬
- 如果第三次失败,八周之后再爬
How to handle dead cycle
- example: too many pages in sina.com, the crawler keeps crawling sina and don't crawl other websites
- Answer: use quota
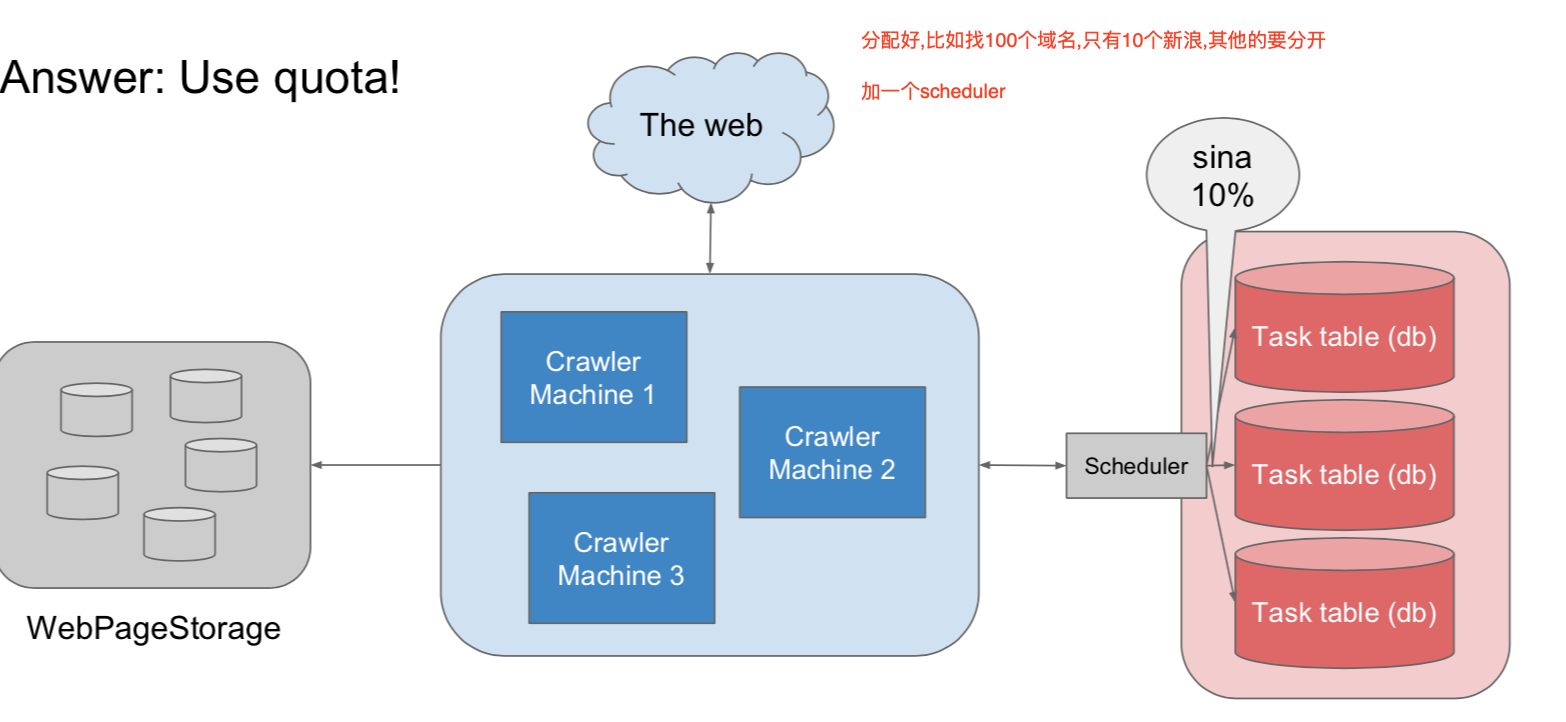
我有空了 去db选择,再返回
Crawler(client) --------> Scheduler(server) --------------> db